
Figure: Global Temperature Anomaly (°C) versus Year. The pink plot is the month-by-month anomalies. The blue plot is the year-by-year anomalies.
We welcome your corrections and questions. Please post both to the comments at the Climate Analysis blog site.
This page serves as a summary of what my friends and I have discovered on the web in our debates about the global climate. We add to it as we have time. We don't make measurements ourselves. We just gather other people's measurements, compare them, and examine their conclusions. It is our habit to be skeptical of all claims by all scientists, including ourselves. But we hope very much that nothing we write here shows any sign of disrespect to anyone working in the field of climate science, to whom we are in debt for all their hard work gathering data, and their further hard work making that same data available to the public.
Despite rumors we have read on the internet about climate scientists trying to keep their data secret, in our experience, every climate science institute has gone out of its way to make its data available to amateur, armchair climate scientists like us. Furthermore, they have posted their papers on the web for us to view, without paying fees to journals. As far as our experience goes: that's better freedom of information than we have in Physics or Electrical Engineering.
We use several simple concepts and phrases in our analysis. Although they are simple, they are nevertheless difficult to understand. Well, maybe you can understand them easily, but it took us years to understand them properly. For a guide to our terms of order, precision, accuracy, and calibration, see here.
We begin with a discussion of global surface temperature. This discussion quickly becomes detailed and rather complicated. It is impossible to avoid these details and complications. The concept of "global temperature" can be vague only until we try to measure it. If we want to measure "global temperature" to 0.1°C, we must be so extremely specific in our definition of "global temperature" that complicated detail becomes absolutely necessary. The purpose of our Global Surface section is to show you how these complicated details arise, and show you how the details allow us to estimate the accuracy of our final measurement.
You will find our large data files and an Excel spreadsheet with our graphs and calculations combined in a zip file Climate.zip.
[09-OCT-24] Suppose we have ten sick people. Dr. Quack persuades them to take his Patent Medicine. Five of them die and five of them recover. Dr. Quack says, "My medicine saved five lives!" But Dr. Nay says, "Nonsense, your medicine killed five people." Both claims are 100% consistent with the facts, and yet they are contradictory. Consistency with the facts is a necessary quality for a scientific theory, but it is not sufficient. If we allow consistency with observation to be sufficient proof of a theory, we are practicing pseudoscience. The Food and Drug Administration (FDA) rejects both Dr. Quack and Dr. Nay's claims, saying the Patent Medicine has absolutely no effect upon the recovery of the patients until experiment has proved otherwise.
The FDA has adopted the null hypothesis. The null hypothesis is the foundation of scientific reasoning. We determine the null hypothesis with Occam's Razor, by which we cut off any unnecessary parts of our hypothesis until we arrive at the simplest possible explanation of our observations. And the simplest possible theory about the relationship between one thing and another is that there is no relationship at all. The only way to disprove the null hypothesis, according to scientific method, is with observations. Compelling arguments and sensible speculation are insufficient, nor is consensus among scientists, nor the authority of experts.
When it comes to the climate, our initial null hypothesis is that the climate does not vary at all from one year to the next, nor does its carbon dioxide concentration. We will have to disprove this with observations before we can begin to discuss how humans might cause climate change. So let us look at what observations are available to disprove this hypothesis. We observe valleys carved by glaciers in warm climates. We find fossils of tropical plants in cold places. We pull out ice cores and they suggest the Earth's temperature has varied dramatically in the past few hundred thousand years, along with its atmospheric carbon dioxide concentration. These observations and many others disprove our null hypothesis. The climate does vary. It varies dramatically and naturally, whithout any human influence. This is our new null hypothesis. We call it the theory of natural variation.
So far as we are concerned, the only way to disprove the null hypothesis is with an observation of nature that contradicts the null hypothesis. We can use the infra-red absorption spectrum of carbon dioxide to argue that doubling the carbon dioxide in the atmosphere will warm the planet (by roughly 1.5°C if we ignore clouds, and 0.9°C if we account for clouds, according to our own simulations). But this is a calculation, not an observation of nature. We may have a compelling reason to suspect that our CO2 emissions are warming the climate, but we cannot abandon the theory of natural variation until we have observations that disprove it.
Even if we accept that increasing carbon dioxide traps heat somewhere in the atmosphere, this does not neccessarily mean that the climate will, as a whole, warm up. It may seem obvious that lighting a fire in my fireplace will warm my house, but the reality is that the bedrooms get cold when I light a fire. That's because the thermostat is near the fireplace, so when I light the fire the radiators turn off. The climate is a complex system. It could be that it contains similar surprises, where we observe the opposite effect to the one we expected. In fact, looking at the ice cores, it appears that atmospheric carbon dioxide increases occurr one thousand years after increases in temperature, which could mean that carbon dioxide somehow stops the world from getting any warmer at the end of an ice age, by a process that we don't understand.
So far as we can tell, scientific method, when applied to our observations of the Earth's climate, arrives at the assumption that the climate varies dramatically and naturally, and that human carbon dioxide emissions have no effect upon it. We look forward to seeing this assumption disproved by observations of nature, but so far we have been disappointed.
The Climatic Research Unit (CRU) in England estimate the average global temperature from the year 1850 until the present day. They maintain their data on their website, and answer basic questions about their methods also. The original scientific paper presenting their measurements is Jones, P.D., New, M., Parker, D.E., Martin, S. and Rigor, I.G., 1999: Surface air temperature and its variations over the last 150 years. Reviews of Geophysics 37, 173-199. The paper concludes that the average temperature of the earth has risen by 0.6°C in the last fifty years.
We downloaded the global mean temperature data from CRU at the end of 2006 (you can find the latest data here). We re-formatted the data to make it easier to plot, here. We took the average of their monthly anomalies (we'll explain what an anomaly is later) and made a table of yearly anomalies as well, which you will find here. We plotted both in the graph below.
Jones et al of CRU collected the measurements made by many land-based weather stations. For a map of the locations of the weather stations, see here. Below is a graph showing the total number of weather stations available in each year, plotted alongside the CRU trend.

The CRU measurement of global temperature starts with around 250 stations in 1880. The number of stations rises to a peak of 8200 stations in 1970. From 1970 to 2000 the number of stations drops from 1600 to 400. During that same period, the CRU global temperature estimate rises by 0.6°C.
We downloaded the monthly global mean temperature data available from the National Climatic Data Center (NCDC). We obtained the data file from here, and add their monthly anomaly corrections to get this data, which we plot below.
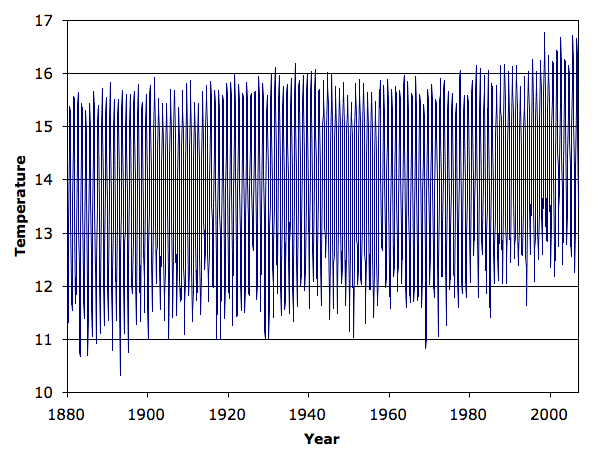
As you can see, the global temperature varies by 4°C during the year. We can greatly reduce this cyclic variation by subtracting the average January temperature from all the January measurements, and the average February temperature from all the February measurements, and so on, to obtain temperature anomalies. When we do this to the NCDC data, we get the a graph similar to that published in Jones et al. Phil Jones of CRU confirms that the two data sets are the same. There are differences in the way the data is combined, and CRU used older measurements in the data to extend their record back another thirty years. You will find the NCDC paper on their analysis here.
Jones et al address many potential sources of error in the way they combine temperature measurements. For example, one source of error is the warming of weather stations as cities build up around them. This effect can be up to +10°C on a hot day. The urban effect would tend to give the impression that the global temperature has risen. Jones et al site work by other scientists that claims these urban effects will contribute less than 0.1°C to Jones et al's observed 0.6°C rise in global temperature. Let us accept this claim for now, but we dispute it below in Disappearing Stations.
Suppose we consider picking a place on the surface of the globe at random. What will its temperature be? The hottest place in the world we could find is El Aziza, where it can get to 60°C on a summer day. The coldest place we could find was Antarctica, where the temperature once dropped to −90°C. Just before we pick a place on the globe at random, the instantaneous temperature we will soon obtain with our thermometer in that place is a random quantity with a near-gaussian distribution. (If you doubt the near-gaussian distribution, please consult the Central Limit Theorem). This random quantity has a maximum, and very rare, value of 60°C, and a minimum, and very rare, value of −90°C. When the spread of very rare values is 150°C, the standard deviation of a gaussian distribution is roughly six times smaller, or 25°C. (See here for a graph off the gaussian distribution, showing that a six-sigma spread encloses 99.8% of all values.) We define the instantaneous global temperature as the expected value of annual temperature. In other words, if we covered the globe uniformly with an infinite number of accurate thermometers, the average value of all their measurements would be the instantaneous global temperature.
If, on the other hand, we put a finite number of thermometers at random places around the globe, and take the average of their measurements, we get an estimate of the instantaneous global temperature that itself has a gaussian distribution. Jones et al start off with roughly 250 measurements of global temperature in 1880, so let's consider what happens if we use 250 measurements distributed around the globe. The average of 250 measurements each with standard deviation 25°C is a measurement with standard deviation 25°C/√250 ≈ 1.6°C.
The instantaneous temperature at any place includes its day-night variation and its summer-winter variation. Suppose we take the average of temperature measurements every hour throughout the year, and call this the annual temperature. We pick places on the globe at random and calculate the average of their annual temperatures instead of their instantaneous temperatures. The annual temperature in Death Valley is 25°C, and at the South Pole it's −55°C. These are among the hottest and coldest places on Earth. One is 80°C colder than the other. Let us once more divide the maximum variation by six to obtain our standard deviation: the standard deviation of annual temperature across the globe is 13°C. We define the annual global temperature as the expected value of annual temperatures. In other words, if we covered the globe uniformly with an infinite number of accurate thermometers, took measurements for a year to obtain the annual temperature at each of our infinite number of locations, the average value of all their measurements would be the annual global temperature.
If we pick 250 thermometers at random places around the globe (once again, we are using 250 because that is the number Jones et al started with in 1880), record their measurements for a year, calculate each location's annual temperature, and then take the average of all 250 annual temperatures, we arrive at an estimate of the annual global temperature. This estimate has standard deviation 13°C/√250 ≈ 0.8 C.

But if you look at the figure above, you will see that the distribution of thermometers in the data used by CRU and NCDC is not random. They are clustered together, and these clusters change as time goes by. In 1850, there were far more weather stations in the northern hemisphere than the southern, and we can imagine that there were far more in Europe than there were in Africa. Given that our 250 thermometer locations are not chosen randomly, we will not get the factor of √250 improvement in accuracy by averaging all of their measurements together.
If we don't get an improvement of √250, what improvement do we see when we average the 250 measurements? We look at the clusters and ask ourselves, if we distributed thermometers randomly, how many could we distribute before they started to look more evenly-distributed than our actual clusters? This exercise gives us a measure of the actual randomness in our clusters. So, we looked at the clusters. The south pole gets left out, Brazil, Australia, and Russia are hardly measured. But we could easily distribute 25 thermometers across the globe and have them under-represent three or four large areas, as does the distribution of the available stations. We're guessing the effective number of independent measurements from our existing clusters is something like 25, in which case our global average temperature has error 13°C/√25 = 3°C because of poor distribution of stations. This error is not random from year to year, but varies as the set of stations grows and shrinks.
Jones et al do not claim to know the annual global temperature to 0.1°C. Instead, they claim to be able to measure changes in the annual global temperature to 0.1°C. To see how these two claims are different, suppose you have a home thermometer and it tells you that the temperature in your house is 30°C, when you know perfectly well that it's closer to 20°C. What does it mean when your home thermometer tells you that the temperature in your house is 29°C? Most likely, it means that the temperature went down. Your thermometer may measure the temperature to only 10°C accuracy, but it can measure changes with 1°C resolution.
We will now take a paragraph or two to explain how Jones et al combined their weather station measurements to obtain their estimate of the change in annual global temperature.
For each month of measurements obtained from each station, Jones et al calculated the average temperature for the month, and subtracted from it the average temperature in that same location for that same month during an arbitrary reference period. This difference they call the station's monthly anomaly. For their arbitrary reference period, they chose 1961 to 1990.
The reason that Jones et al choose 1961-1990 for their reference period is because this is the period has the largest number of active land-based weather stations. In the Anomaly Versus Absolute Temperature of their paper, they say:
In this analysis, 12,092 station estimates of mean temperature for 1961-1990 are used to construct a 0.5° latitude by 0.5° longitude climatology for global land areas excluding Antarctica.
Consider, for example, a weather station on the coast of Australia in 1850 that operated for twenty years. We use the 1961-1990 temperature map to obtain the average temperature at the weather station's location from 1961-1990. We subtract this temperature from the weather station's measurements to obtain its anomalies. Every year, we have hundreds to thousands of anomalies from stations all over the world. We take the average of all of them to obtain our estimate of global anomaly. The global anomaly is what we show plotted in the graphs above. We show both the monthly and annual global anomaly.
If we assume that our weather stations in the reference period are well-distributed, then the method of anomalies helps remove errors that arise from poor spatial distribution of weather stations outside the reference period. If we have only a few weather stations in 1850, we don't have to worry so much that they are in mostly hot areas or mostly cold areas. We are comparing each station to the climate in the same location a hundred and twenty years later, when we have many more weather stations.
The use of anomalies also helps us remove errors that arise from changes in our set of available weather stations. Suppose we have nine weather stations around the world, whose average annual temperature is 10°C from 1900 to 2000. We want to combine these measurements with those of a weather station in Antarctica that was founded in 1950. We can't add Antarctic measurements before 1950, because they don't exist. The moment we start adding the Antarctic measurements, our average annual temperature will drop by 5°C, because the annual temperature in Antarctica is around −50°C. The method of anomalies avoids this −5°C.
The method of anomalies greatly reduces errors due to changes in our set of available weather stations. It greatly reduces errors due to temperature offsets between weather stations. With these two errors greatly reduced, we might hope to see only changes in the global annual temperature, and this is indeed the claim made by Jones et al. They claim to be able to measure changes in global annual temperature with 0.1°C precision. Let us estimate for ourselves the accuracy with which the method of anomalies can measure trends in global annual temperature.
Consider the central England temperature over the last three hundred years, which we present elsewhere. Suppose we had only a ten-year stretch of data from Central England, and we used the anomalies from this ten-year stretch in our estimate of the global anomaly. The figure below shows the trend in°C/decade we would obtain using the previous ten years of Central England measurements, plotted against the year. The standard deviation of the ten-year anomaly trend is 0.7°C/decade.
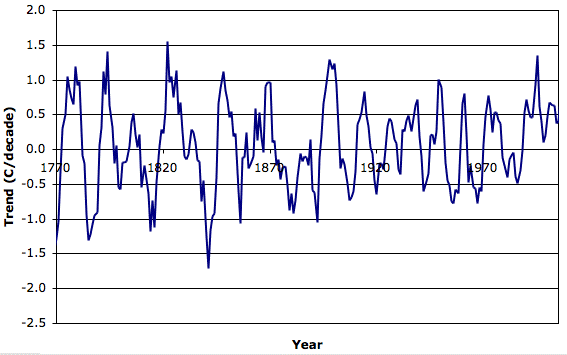
If we plot the same graph for shorter or longer periods, we find that the standard deviation of the trend is close to 0.7°C/T, where T is the length of the period. So the half-century trend has standard deviation 0.7°C/half-century.
Let us suppose Central England is representative of temperature variations around the globe. If we have twenty-five weather stations distributed evenly about the world and we combine ten continuous years of measurements with the method of anomalies, we will obtain an estimate of the decade-long global temperature trend that has standard deviation 0.7/√25 = 0.14°C/decade. If we combine fifty continuous years of measurements we will obtain an estimate of the half-century-long global temperature trend with will have standard deviation 0.14°C/half-century.
We can understand how CRU and NCDC believe it is possible to use their method of monthly anomalies to determine changes in global temperature with 0.1°C resolution. But they have not proven their accuracy by comparing their method with another, independent method that is accurate to 0.1°C for the same time period.
The distribution of weather stations in the CRU and NCDC data set is non-uniform across the globe and with time. Because of poor distribution, the effective number of stations can be hundreds of times smaller than the total number of stations.
Another reason to doubt the accuracy of the CRU and NCDC trends is that the data from almost all stations is incomplete. The addition and subtraction of stations from the calculations is bound to introduce systematic errors. When we look at the CRU graph of global temperature, we see a clear correlation between the number of weather stations used and the rise in temperature in the last fifty years. As the number of weather stations drops from 1955 to 2005, their estimated global temperature rises. We look into this correlation in more detail below, and show that it appears to introduce a false warming of order 0.2°C.
The fact that CRU and NCDC trends agree suggests that their application of the anomaly method to the same set of data is free of errors. Indeed, we come up with almost exactly the same results from the same data set, but using a very much simplified analysis, as we present below, so we are convinced that they have both done their analysis accurately. But this agreement does not verify the anomaly method itself. We cannot confirm the CRU and NCDC trends by comparing them to a more accurate measurement method. There is no more accurate measurement method. Climate scientists tend to use the CRU and NCDC measurements to calibrate their own trend measurements. Nor can we even determine the precision of the method by measuring the global temperature for a century during which it remained constant. There is no century during which we know the global temperature was constant.
Perhaps as a result of our own ignorance, or perhaps out of a contrary disposition, we remain skeptical that the resolution of the CRU and NCDC measurements is 0.1°C. We see no mention of the correlation in Jones et al's paper, and no effort to show the correlation is mere coincidence. We estimate that their global trend contains systematic errors of order 0.1°C/decade.
We are not alone in our skepticism. The paper Unresolved Issues with the Assessment of Multi-Decadal Global Land Surface Temperature Trends (available here) argues that the effects of new buildings, loss of vegetation, change in instrument elevation, and changes in the instruments themselves, produce systematic errors in the global trends that could easily be of order 1°C. For example, they show how a change in land-use and land-cover (they say LULC) causes the sudden appearance of positive trends in a collection of a hundred or so neighboring stations (see their Table 5).
We resolved to look at the raw data ourselves. For our results, see below. Our home analysis allowed us to estimate the systematic error caused by the disappearance of weather stations.
Let us suppose that Jones et al of the Climatic Research Unit are correct, and their measurement of global temperature is indeed accurate to 0.1°C. Can we look at their graph and predict a trend? How do we know that the fluctuations in global temperature are not random?
What we see in the Jones et al graph are variations from year to year of around 0.1 C, variations from decade to decade of 0.2 C, and variations from century to century of 0.4 C. This looks like the 1/f noise, or pink noise, we see in many physical systems. When we test for pink noise in physical systems, we take the fourier transform of whatever data we have available, and compare this transform to the ideal pink-noise transform.

The transform of ideal pink noise is smooth because we use an infinite number of measurements to obtain the transform. The CRU transform jumps up and down because we have only a couple of hundred years of annual measurements for the transform to work on. But the overall shape of the transform conforms well to the pink noise transform from 0.01 cycles/year (that's cyclic changes that take 100 years to complete) up to around 0.5 cycles/year (two years to complete). After that, the transform levels out, in a manner consistent with white noise.
The global temperature trend looks like pink noise. Before we can say that a rise in temperature is a trend we first have to prove that the global temperature is not random. To prove that it's not random, we need a lot of accurate data. We don't have that data. We cannot even repeat our historical observations. The past is gone. Nor can we perform control experiments upon our climate to distinguish between deterministic and random behavior.
Indeed, if it were that easy to predict trends from chaotic-looking graphs like the global temperature history, we'd all be millionaires in the stock market by now. Just look at the graph above, and see if you can tell what the stock is going to do next. To see what happened next, click here.
We conclude that we must not draw any conclusions about the future of the climate from the CRU trend alone.
When we perform an experiment, we usually start with a hypothesis about what the results will be. If the result matches our expectation, we stop working and present our results. If our result does not match our expectation, we look for errors in our measurements. When we find an error, we correct it. The errors we are looking for are ones that cause our results to deviate from our expectations.
You can see an example of this expectation-driven search for errors below. The scientists at Michigan State University expected their measurements to agree with those of the Climate Control Unit, and when the results disagreed, they looked for ways to alter the results. They found one way, and applied it. The book How Experiments End gives further examples of the same phenomenon occurring in experimental physics.
There's no way to avoid this expectation-driven search for errors. On the one hand, we are busy, so we won't look for errors when there don't appear to be any. On the other hand, when our results are wrong, we are inclined to check our work. But it we must not allow our expectation-driven search for errors to escalate to outright data-manipulation, which we call data massage. The result of data massage is that agreement between different measurements loses its significance, because the agreement is artificial. The following actions are the sorts of things that cause data massage.
Data massage is not the same as scientific dishonesty. It's merely one of the many mistakes we can make as we try to do the best job we can with our data. We try to identify corrupted data, but there's always a risk that our expectations will lead us to mistake good data for corrupt data, despite our best efforts to the contrary. Well, that's our experience: we claim to know a thing or two about data massage, because we have been guilty of it ourselves many times.
Here's a graph that strikes us as a good example of data massage. If someone presented the graph to us in a conference, we would have a few questions to ask about it. The graph shows a selection of global temperature estimates. (We obtained the graph from here.)

The measurements agree with one another in the past fifty years, but disagree everywhere else. It is impossibly unlikely that five independent temperature measurements would agree to within 0.1°C in the past fifty years, but disagree as much as 0.6°C everywhere else. The measurements are not independent. They have been massaged until they agree with one another during that fifty-year period.
We can't be sure exactly how the massaging took place, but we can guess. Two groups came up with two independent temperature measurements. They disagreed. They called in a third group, and tried to figure out what was wrong. Some time later, a fourth and fifth groups joined the discussion. They were most disappointed by their disagreement over the past fifty years, because that's the period for which they had the richest data. They started to look for errors in their methods, and identify corrupted data points. They adjusted weighting factors and calibration constants in ways that made sense in the light of their shared discussions. They investigated data points that were far removed from others, and often found reasons to doubt and reject those data points. After a while, their measurements agreed well over the past fifty years, and that's when they let themselves get some rest. Their measurements still didn't agree over the long-term, but they had done all they could, as diligent scientists, to set things right.
Extra: Timothy Chase was kind enough to provide us with a detailed explanation for how the above graphs fell into agreement. You can read his explanation here. He describes how the temperature measurements are calibrated using the same "instrument-based" record of the past fifty years. He states that such calibration is standard practice in climatology. Our description of the process by which the graphs came into agreement is incorrect, but the result is the same. The agreement of the various measurements is of no significance, and yet the agreement appears to have significance when we look at the graph.
Extra: The temperature measurements from tree rings appear to have been curtailed from 1960 and from 1402 to 1550 in order to get them to match the overall hockey stick shape of the above graph. For explanation, see here.
The reason data massage is so dangerous to science is that it's hard for people who did not do the work to spot it, and because the ways in which data can be massaged can be so complex as to confound our efforts to see through them. The way we defeat data massage is to encourage lively debate, fund contrary scientists who wish to disprove our results, and check every result we can by duplicating it in an laboratory setting.
[07-SEP-25] There are some weather stations that were rural when they were founded, and remain rural today. One such center is the Armagh Observatory in Northern Ireland. The record of Armagh temperatures for the last two hundred years is here. The Armagh Observatory shows no significant rise or fall in temperature over the past two hundred years.
The Hadley Center maintains an average Central England Temperature for the past three hundred years. The figure below plots the monthly and annual average central England as downloded from their site in 2009. The data was here, but is no longer available.
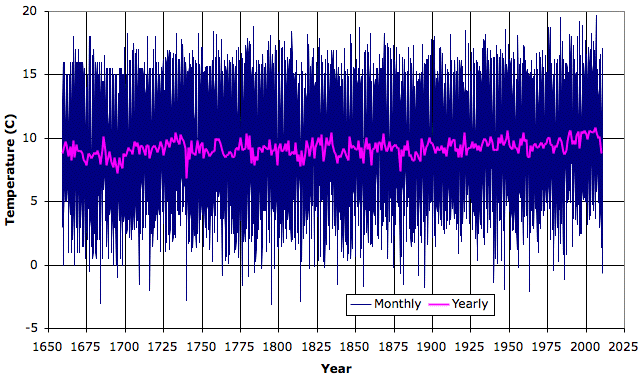
Since 2009, the Hadley Center has gone back and altered the temperature measurements for central England, and now the measurements show a significant warming since 1980, as you will see here.
Even if we had a hundred weather stations like Armagh, we would be hard-pressed to produce a global average temperature estimate accurate to 0.1°C in the way the Climatic Research Unit and the National Climate Data Center have done (see above). But we don't have anything near as good as one hundred centers. We have hundreds of disparate, short-lived, and urbanized weather stations.
By pulling ice out from the polar ice caps, we can measure the temperature of the ice caps hundreds of thousands of years ago, and the atmospheric concentration of carbon dioxide (CO2). These lumps of ice are called ice cores. The temperature measurement comes from the relative concentration of isotopes in ice crystals, and the carbon dioxide content comes from gas bubbles trapped in the ice.
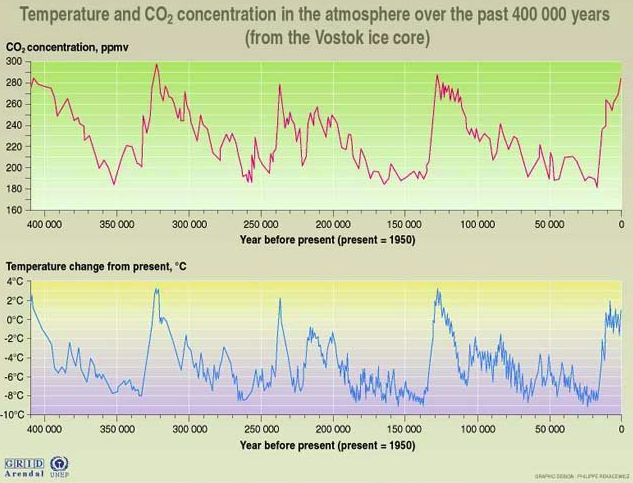
As you can see, carbon dioxide concentration rises when the world is warmer. Some students of ice core studies dispute the absolute accuracy of their measurements of both concentration and chronology. We have not looked into the matter far enough to have an opinion.
Regardless of accuracy, the ice core temperature measurement appears to be a thousand-year average. It is insensitive to century-long fluctuations in temperature. The same is true for the carbon dioxide concentration. But the dates of the two measurements are hard to match up, because gas bubbles rise up through the ice, so that the gas measurements tends to pre-date the temperature measurement as we drill down into the ice. Nevertheless, ice core scientists have worked hard to account for these effects. The ice core teams agree that changes in carbon dioxide concentration lag behind changes in temperature by a few hundred years to a few thousand years. If you have access to science journals, you can take a look at Fischer et al, 1999, where they deduce a lag of 400 to 1000 years, and Caillon et al, 2003, where they deduce an 800-year lag. We discuss the implications of this eight-hundred year delay in the following section.
As an example of ice-core data, here is some raw data from ice cores in Greenland, collected by D.Dahl-Jensen et al., who we believe are Danish scientists. Their preamble contains the statement, "Details about the temperature history are lost as we go back in time. The curves become more and more average curves." For a plot of their data over the long-term, see here, and in more recent times, see here.
The concentration of carbon dioxide in the atmosphere is now at around 0.04% by volume. According to graphs like this one, the concentration was closer to 0.02%. But then again, according to other observers, the historical measurements of CO2 concentration are not to be trusted. Indeed, the graphs that show a recent spike in concentration are all, without exception, made up of two sources of data spliced together without declaring as much to the viewer. Looking at geological timescales, the concentration of CO2 in the past was far higher than it is today. According to Kaufman et al, who studied carbon isotopes in microscopic fossils, the carbon dioxide concentration a few billion years ago was between ten and two hundred times higher than it is today. According to Dr. Geoff Deacon, the concentration 600 million years ago was ten percent.
Plants build their bodies out of carbon dioxide and water with the help of sunlight. A billion years ago, before the evolution of plants, carbon dioxide in the atmosphere was in equilibrium with that dissolved in the ocean and other reservoirs. Carbon dioxide entered the cold oceans and left the warm oceans. Cold water can hold more carbon dioxide than warm water. You can see this for yourself in your own kitchen. Take some sparkling water and pour it into a pan. Stir it around a bit and leave it to sit for a few hours. It will stop bubbling. Now heat it up on your stove. It will start bubbling again, as carbon dioxide comes out of solution. We discuss the effect of temperature upon dissolved carbon dioxide in more detail here. The actual equilibrium between the atmosphere and the ocean is, however, more complicated than the equilibrium between pure water and carbon dioxide. Chemical reactions with other dissolved compounds have a strong affect upon the solubility of carbon dioxide in sea-water.
Once plants evolved, they captured carbon dioxide and converted it into the hydrogen-with-carbon compounds that make up plant matter. With plants consuming carbon dioxide, the concentration of carbon dioxide in the atmosphere appears to have dropped by a factor of between ten and two hundred, to its present-day level of around 0.4%. We are not certain that plants are responsible for this drop in carbon dioxide concentration. We have not yet found any work that proves plants were responsible. It may be the drop in carbon dioxide concentration occurred before the evolution of plants, and is instead a feature only of the complex equilibrium between the atmosphere and the oceans.
Rotting plant matter was buried underground by downward movements of the earth's crust, which geologists call subsidence. Under pressure, and in the absence of oxygen, the plant matter turned into coal and oil. Now we are digging the coal and oil out of the ground and burning it, which converts its hydrogen-with-carbon compounds into carbon dioxide and water. As a result of this burning, it appears that the concentration of carbon dioxide has risen to 0.04%. Once again, we cannot be certain that our burning of fossil fuels is responsible for the rise in carbon dioxide concentration. The rise could instead be a fluctuation in the equilibrium between the atmosphere and the oceans.
One thing we can say for sure about the carbon dioxide we release into the atmosphere by burning fossil fuels: it's going back where it came from.
When you burn hydrocarbons (compounds of carbon and hydrogen), you get carbon dioxide and water. When bacteria and animals digest plant and animal matter, they combine it with oxygen, which is equivalent to burning it: you get carbon dioxide and water also. Methane is the simplest hydrocarbon. Here's what happens when you combine it with oxygen.
CH4 + 2O2 --> CO2 + 2H2O
One way of looking at the carbon dioxide in the atmosphere is to think of it as one place where the element carbon exists in and around the Earth. The atmosphere is a carbon reservoir. So are the reserves of coal, oil and gas in the ground, which we can group together as fossil fuels. The bodies of all animals and plants, as well as rotting vegetation in soil, is another reservoir, which we can group together as the world's biomass. The oceans are a carbon reservoir, by virtue of the carbon dioxide dissolved in them. We downloaded the following figure here, from the Woods Hole Research Center. It shows the Earth's carbon reservoirs, and gives their estimates of the rate at which carbon is moving from one to another every year. The ocean is divided into two parts, which we believe are the surface layer of the ocean and the deep layer.
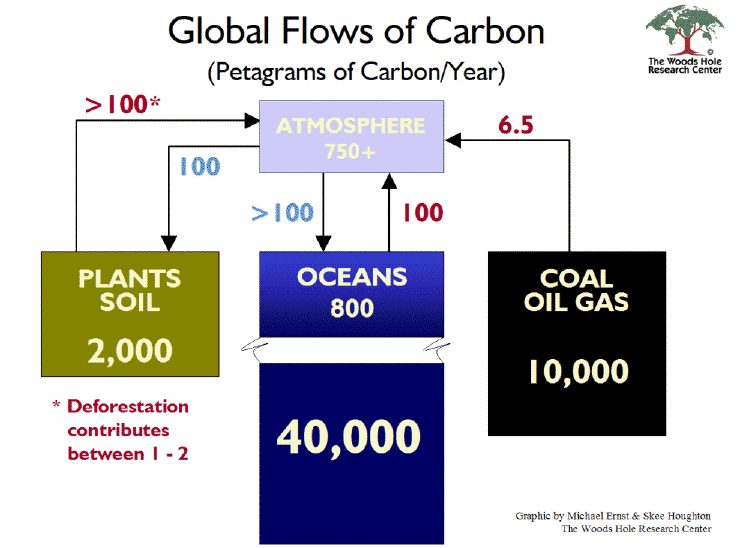
You will find another graphic, with similar numbers, here, at the IPCC site. There are roughly 750 Pg of carbon in the atmosphere. The human contributions to the carbon cycle are the burning of fossil fuels and deforestation. Together these represent around 8 Pg (eight petagrams, or 8×1015g or 8×1012kg). Meanwhile we have roughly 100 Pg entering the world's biomass every year as new plants and animals grow, and another 100 Pg leaving as old plants and animals decompose. Another 100 Pg is dissolved in the ocean in some places, while 100 Pg comes out of solution in other places.
The total release of carbon into the atmosphere from natural sources is around 200 Pg, and the total absorption is also 200 Pg. The natural sources and absorption are in equilibrium. The natural concentration of atmospheric CO2 varies only by a few parts per million per year, as we can see here. The simplest chemical equilibrium is one in which absorption is proportional to concentration. Absorption is 200 Pg/yr when we have 750 Pg in the atmosphere, so the absorption rate could be 0.27 Pg/yr per petagram of atmospheric carbon. If we denote the atmospheric mass of carbon as MA, then dMA/dt denotes the rate of change of MA in Pg/yr and we have:
dMA/dt = 200 − 0.27 MA Pg/yr
The human contribution is 8 Pg/yr. With this contribution, the atmospheric carbon mass will increase until absorption once again balances emission. We need 8 / 0.27 = 30 Pg more carbon in the atmosphere to reach equilibrium. Now we have 780 Pg of carbon in the atmosphere. In terms of atmospheric concentration, a 4% increase in emission leads to a 4% increase in concentration, so if we start with 330 ppmv CO2 in pre-industrial times, today's 8 Pg/yr carbon production will cause the CO2 concentration to increase to 340 ppm. As it is, atmospheric carbon dioxide has increased to 400 ppm. To the first approximation, 60 ppm of this increase is natural.
Let's try to put an upper limit on how strongly carbon dioxide contributes to the warmth of the world. The carbon dioxide concentration a billion years might have been as high as 8%, or as low as 0.4%, but still much higher than today's 0.04%. The temperature of the Earth was roughly the same. But the sun was weaker. We're not sure by how much, but more than 10% less bright than today, and perhaps as much as 50% less bright. The sun on its own warms planets. It warms the moon. The moon gets very cold at night, and warm during the day. The earth itself is a ball of molten rock, and heat emerges from it through the crust. The Earth was itself hotter a billion years ago. All these factors make it difficult for us to put an upper limit on how strongly carbon dioxide contributes to the warmth of the world. All we can say is: there used to be a at least ten times more of it in the atmosphere, and the world was not much warmer.
Ice cores allow us to measure carbon dioxide concentration hundreds of thousands of years ago. As we noted above, the ice-core carbon dioxide measurement is a thousand-year average. It is misleading to add to the end of an ice-core measurement our recent year-to-year carbon dioxide concentration measurements, as someone has done here. The graph suggests that there were no short-term fluctuations in carbon dioxide concentration before the modern era, but the ice-core measurement is insensitive to short-term fluctuations. Many such fluctuations could have occurred in the past.
According to ice cores, carbon dioxide concentration changes lag behind temperature changes by around a eight hundred years. Therefore, we reject the claim made by some climate scientists that carbon dioxide is a potential cause of global warming in pre-historic times. If one thing is going to cause another, it must occur first.
Aside: Some commentators on climate history claim that carbon dioxide did cause the pre-historic temperature changes. They start with a presentation of Milankovitch Cycles. These are slight changes in the orbit of the earth around the sun, causing slight changes in the heat delivered by the sun to the earth. So far as we can make out, the theory from this point goes something like this: the slight rise in heat received by the earth causes an initial rise in carbon dioxide concentration from around 200 ppm to around 240 ppm, which in turn causes a sudden run-away warming of the atmosphere, but after that the heat-trapping power of the carbon dioxide ceases to be significant and carbon dioxide concentration continues to rise after the world has reached its new warm temperature. It's not cleaer to us how the run-away carbon dioxide effect is necessary as an explanation for the end of an ice age. Once the white, reflective ice starts to melt, the earth will absorb more heat, and more ice will melt. This is a phemonimenon we can test easily with a glass box, a heat lamp, and some snow covering a black mat. On the other hand, it may be that we have not taken enough time to understand the theory. We are not inclined to study the theory because it is a complicated theory that attempts to explain simple observations. We prefer simple theories that explain diverse and complicated observations. Perhaps we are lazy. In the case of this theory, however, our confusion is compounded by the fact that those who argue in its favor go on to argue that the same run-away temperature rise is going to happen in the near future if we allow carbon dioxide concentration to rise above 400 ppm. But their theory is based upon the assumption that all run-away warming caused by carbon dioxide stops above around 250 ppm. Some of our readers feel that we should pay more attention to the Milankovitch Cycles, and one has supplied us with an enlightening summary.
It is possible that temperature changes cause changes in carbon dioxide concentration. Warm air warms the oceans, and this would cause the oceans to release carbon dioxide into the atmosphere. But the simple fact of a correlation between temperature and carbon dioxide does not prove that one causes the other. Warming oceans will release carbon dioxide, but we have not proved that they will release enough carbon dioxide to account for the rising concentration at the end of an ice age.
For a discussion of the greenhouse effect, water vapor, carbon dioxide and the role of the tropopause in cooling the Earth, we point you to our long series of blog posts on the subject, in which we slowly build up what we believe is a clear and accurate picture of the effect. The first post is called The Greenhouse Effect. Our picture of the greenhouse effect is consistent with the laws of physics and thermodynamics as we understand them, but has some striking differences from the greenhouse effect portrayed in the media and other casual scientific documents, even in school textbooks.
The troposphere is the lowest layer of the atmosphere. It is of order 10 km thick. The temperature of the troposphere drops by approximately 7°C per 1 km you ascend from the earth.
The University of Alabama at Huntsville and Remote Sensing Systems use satellite-based radar instruments to estimate the temperature of the lower troposphere. The measurements they produce are called UAH-MSU and RSS-MSU after the MSU (microwave sounding unit) they use to perform their measurements. You will find the UAH-MSU measurements of lower-troposphere temperature here, and for mid-troposphere here. We were unable to find text files of temperature measurements at the RSS-MSU website, but we are confident that the files are available somewhere. The graph below shows both the mid an lower tropospheric anomolies from UAH-MSU.
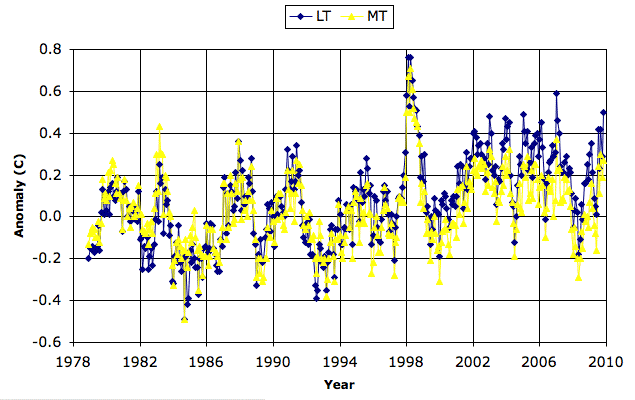
When you transmit microwaves towards the earth from a satellite, most of the microwave energy passes through the intervening atmosphere and reflects off the earth. But some of it reflects off the intervening air, and some very small portion of that reflected energy returns to the satellite, where we can measure it. Microwaves reflected by the stratosphere return one hundred microseconds (one ten-thousandth of a second) before microwaves reflected by the troposphere, because the stratosphere is of order 30 km closer to the satellite. The radar records the amount of energy returning to the satellite as the microseconds go by. In theory, therefore, we can obtain an estimate of the amount of energy reflected by, for example, the troposphere, or even the lower parts of the troposphere, or lower troposphere.
Air reflects more microwave energy if is it more dense, and it is more dense if it is colder. The energy reflected by the troposphere could, in theory, be used to measure the temperature of the troposphere. But we must keep in mind that the troposphere temperature drops by roughly 70°C from the bottom to the top, so it's not clear how meaningful taking an average temperature of the troposphere is going to be. To make a global measurement, we repeat our troposphere measurement millions of times as our satellite orbits the earth. The temperature of the earth varies at any given time by of order 40°C from the poles to the equator, and the colder air is more dense than the warmer air, so we still have to do some thinking before we combine the millions of measurements into a meaningful measurement of average global temperature.
Nevertheless, that's what the scientists at the University of Alabama have been doing: using satellite radar to measure the average temperature of the world, and you see the results above. Many other scientists have done the same. Here is the abstract from a paper on the subject [12-DEC-09 Link broken, one reader says quote is from a scientist called by Giovanni Sturaro].
"The retrieval of the satellite radiant temperature for global climate monitoring is a complex task. It requires strong processing of the raw data, because various corrections are applied to the measurements to solve instrumental inhomogeneities. The lower troposphere signal is derived from the difference of two large quantities thus amplifying errors and noise in the record. The data represents the air temperature averaged over the lower 8 km of the troposphere. A strong debate has arisen over the years because of the discrepancies in the trend between satellite and surface temperature records. Many causes are suggested to explain the differences. Anyway, it is important to consider that the two records are only partially comparable, because the surface and the lower troposphere are two distinct physical entities. For this reason, it is believed that part of the discrepancies is real."
Despite these difficulties, the troposphere measurement appears to be stable to ±2 C from one year to the next, which makes it likely that the precision of the yearly measurements is 1°C or better. If we want to claim better precision than 1°C, we need to show that the variations we observe from one year to the next are real variations. To do that, we must compare the satellite measurements to those made by another method that we are certain of to much better than 1° C.
Satellite radar users compared their satellite measurements to measurements by the Climatic Research Unit (CRU), which we show above. They found that their satellite measurements and the land-based measurements disagreed. The land-based measurements showed an increasing global temperature. The satellite measurements did not. Both UAH and RSS corrected their troposphere measurements for an effect they call stratospheric cooling, knowing that such a correction would bring their measurements more in line with the warming shown by land-based measurements. The graph below shows the corrected measurements from UAH-MSU compared to the CRU trend.
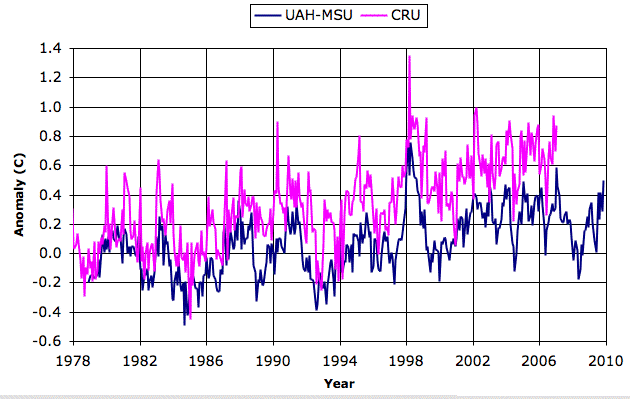
The two graphs show good agreement upon year-to-year fluctuations, especially when we consider all the systematic errors each method must overcome to produce and accurate result. But the two graphs disagree in their slope. If we fit a straight line to UAH graph, its slope is +0.013°C/yr, while the slope of the CRU trend is +0.025°C/yr. The slope of the two lines is important to climate scientists because they believe it has predictive power. We don't think the slope has predictive power, but we believe we can explain why the CRU slope is greater than the MSU slope. The CRU slope is higher because of the effect of disappearing stations, as we discuss below, after we introduce our method for finding systematic errors in the global surface data.
We resolved to look at the raw measurements used by CRU and NCDC to obtain their surface temperature trends. We wrote to CRU, and promptly received this gracious reply, in which Phil Jones points us to the raw data in two places, and invites us to analyze it for ourselves.
The data from all known weather stations is stored by GHCN (Global Historical Climatology Network) here. Their ftp download side is here. We downloaded v2.mean.Z and unzipped it to produce a data file of six hundred thousand lines. Each line in the text file contains twelve monthly average temperatures from one temperature station for one year, as described here. We re-formatted the text file using a Tcl script, which you will find here.
The result is our own data file, called GMA.txt, which you can download in zip file here. You can look a sample of the data here. The first number on each line is the GHCN station code. The next number is the year. The following twelve numbers are the January to December monthly average temperatures at the station.
When there are several recording stations very close to one another, GHCN refers to these multiple measurements of the same location as duplicates. You will find a more detailed description of the data in An Overview of the Global Historical Climatology Network Temperature Database, which you will find here. We remind you that the distribution and starting years of these stations are as shown in this map. The graph below shows the number of stations available in each year. Our number of available stations rises to 8314 in the year 1967. We note that GHCN says the total number of distinct stations in the data set is only 7280 in the year 1967. That's because we counted duplicate stations as separate stations. In other words, if there are three weather stations within a hundred meters of one another, we count them as three separate weather stations. Our total number of stations that appear for at least one year in our data set is 13289. In the year 1967, more than half of these were operational. In the year 2000, only one in seven of them was operational. In the year 2007, only one in fourteen was operational. For a graph of the number of available stations, plotted along with the CRU trend, see here.
We created a new data file, called GYA.txt, containing the same lines as GMA.txt, except the monthly average temperatures are replaced by a single annual average temperature, which is the average of the twelve monthly measurements. To generate GYA.txt, we used the Tcl script here.
We begin by looking at the magnitude of the systematic errors contained in our data set. The graph below shows the global temperature we obtained by taking the average of all available stations in each year. For each year starting with 1800 and ending with 2006, we searched through GYA_1.txt for all available station measurements, counted them, and calculated their average. For this analysis, we switched to Pascal so it would run faster. You will find our Pascal code for our first analysis here. The plot also shows the number of weathers stations for which we have measurements in each year.

The average temperature of the stations rises by 5°C in the past 150 years. We know from continuously-operating weather stations that the upward trend in temperature over the last two hundred years is no more than 1°C/century. The 5°C/century trend in the average temperature of our weather stations is a result of the distribution of weather stations shifting from colder parts of the world to warmer parts of the world, a trend that we can see clearly in our location and starting year map. We must devise a method of analysis that will eliminate this systematic error before we can see the global temperature trend, if there is one. Furthermore, we see that the number of weather stations changes dramatically also, and we must be wary of systematic errors introduced by such dramatic changes in the sources of our measurements. We will investigate the effect of disappearing stations later.
Climatologists use what they call anomalies to reduce these errors. To calculate their anomalies, they first make a reference map of global average temperature for a reference period during which they have a large number of weather stations available. The CRU reference period is 1961-1990, during which they have continuous measurements from over twelve thousand weather stations. To calculate global anomalies from the data ourselves, we need a reference map. For that we need a file mapping our weather station numbers to global positions. We have already presented such map, but we would like to try an alternative analysis, as suggested by our collaborator Julian Hjortshoj. As we will show later, the simplified analysis he suggested is in fact very similar to the one used by CRU and NCDC.
Update: On 19-AUG-10, four years after our initial calculations, this same method is presented by Hu McCulloch at Climate Audit. He calls it the First Differences Method, which must be the correct name. We called it the Integrated Derivatives Method.
For each year, and for each station, we subtract the previous year's annual temperature from the current year's annual temperature. If the previous year's annual temperature does not exist, we ignore the station. By this means, we obtain as many estimates of year-to-year change in global temperature. We will call these the station derivatives. Each year, we take the average of all these estimates to form the global derivative. We integrate the global derivative, and so obtain the global temperature plus a constant. We should be able to see the global trend. Our concern will be any systematic offset in our derivatives, so that we end up integrating a small constant error from year to year, giving rise to a fake trend.
We calculate the station derivatives and the global derivative using this program. We plot the global derivative below. For a graph of the distribution of the derivative, compared to a normal distribution, see here. The standard deviation of the derivative over the entire 1800-2006 period is 0.5°C, and for 1930-1990, when we have over two thousand weather stations, is 0.3°C.

We integrate this curve and subtract its average value to get the global trend centered about zero. The following graph shows the integrated derivative trend as well as the CRU trend and the number of derivatives available each year, which is slightly less than the total number of stations.

The two graphs are almost identical. Our method is a proxy for the CRU and NCDC methods. Indeed, the two methods are almost identical in the way they analyze the data. The only difference between our method and theirs is that we don't make any attempt to find the absolute value of global temperature, nor do we assignn different weights to stations based upon their locations. Our method determines how much hotter one year is than the previous year in exactly the same way as the CRU and NCDC trends, except that our method gives all stations equal weight in the calculation.
Note: Some readers have asked for a more convincing demonstration that our ID (integrated derivatives) method is so similar to the CRU and NCDC methods. We attempt to provide a more convincing demonstration below.
If you apply our method to any set of station data, you will obtain almost exactly the same curve as CRU and NCDC would obtain from the same set of station data. Our readers are welcome to apply our method to other sets of data and compare the result to a CRU or NCDC trend obtained from the same data, in an effort to falsify or strengthen our claim.
Given that we can generate the same curve with a calculation that takes no account of distribution, disappearance, nor urban heating, we can say with confidence that one of two things must be true for each of these sources of error: either it does not exist in the data, or CRU and NCDC failed to compensate for it. In the following section we show that disappearing stations have a strong effect upon undelying data. We conclude that the CRU and NCDC methods have failed to account for the loss of most of their weather stations between 1960 to 2000, which is precisely the period when their curve shows such sustained warming. Because urban heating is intimately related to station disappearance, we doubt that the CRU and NCDC methods performed any compensation whatsoever for urban heating. As to geographic distrubution, it may be that the error due to geographic distribution is small when considering the global trend, or it may be that their method of grids is ineffective at compensating for distribution error. Either way, the gridding achieves very little. Our original graph of the average temperature of the available weather stations in each year shows that the distribution of weather stations is moving into warmer climates as time passes. In order to examine this potential source of error in the trend, we will have to relate stations to locations, which we plan to do at some later date.
According to the Berkeley Earth Surface Temperature (BEST) project, the number of available stations is very much greater than the number used by GHCN. The BEST project documentation claims that there are roughly fifteen thousand stations reporting daily from 1970 to 2010, but GHCN rejects almost all of them with its inclusion criteria. By selecting 2% of the fifteen thousand stations, BEST tested its processing code without any corrections for systematic errors, and arrived at a trend similar to that of CRU and NCDC, and indeed similar to the trend we arrived at before we applied any corrections to the data.
Imagine a weather station in a field just outside New York City one hundred years ago. The breeze wafts gently across the field, passing through the grass, over a little stream, and through the station. Fifty years later, the second world war is over, and New York City expands. A developer buys land up to the edge of the field containing the station. The breeze wafts through the car park of a new apartment building, passing over the hot black tarmac in summer. The temperature recorded by the station rises. After another ten years, a developer buys the field containing the weather station, and the weather station is dismantled. It no longer provides measurements for our global trend.
The rise in surface temperature caused by urban development is well-known. It's called the Urban Heat Island effect. Surface temperatures in cities are of order 2°C higher than they would be in the same place if the city were absent. If a city builds up around a weather station, pressing close about it, we can expect the weather station to show a warming trend of order 2°C in the process. If the process takes twenty years, we might see a +0.1°C/yr trend. The weather station disappears at the end of the twenty years, when someone buys the land out from under it to make space for a building.
Examples: One of our readers, Peter Newnam, writes to us from Australia and provides us with two compelling examples of urban heating. One is Empirical Estimation of the Effect of Urban Head Advection on the Temperature Series of de Bilt, T. Brandsma et al, International Journal of Climatology, 23: 829-845 (2003). We provide a copy of the paper here. The paper describes the effect of moving a weather station a few hundred meters from within a town to outside the town. The second example is Urban Heat Islands and Climate Change - Melbourne, Australia, C. J. G. Morris. We provide a copy of this report here. The paper describes the effect of urban development around Melbourne.
Many people have looked into the potential effect of urban heat upon the global trend calculated by CRU and NCDC. Some have concluded the effect is small. Others insist that the effect is large. The arguments of those who claim the effect is small are based upon observations of stations that did not disappear from the temperature record, and which can therefore be compared to rural temperature measurements over the past fifty years. They found that urban weather stations tend to reside in parks and on coastlines, which are cooler than the city. They call these urban locations cool islands.
But our concern is not with weather stations that remain in cities and therefore remain in the temperature record. Our concern is with the weather stations that disappeared from the cities and therefore disappeared from the temperature record. We do not know for sure that the dramatic drop in the number of weather stations over the last fifty years is entirely due to urban development around and ultimately on top of the disappearing weather stations. But we are certain that an analysis of the remaining weather stations in their cool islands does not help us estimate the effect of disappearing weather stations upon the global trend. Our suspicion is that these disappearing stations were not in permanent cool islands, but rather were overtaken by urban development.
The number of available weather stations used by NCDC and CRU in the calculation of their global trend dropped from roughly 1700 in 1960 to 400 in 1990. To the first approximation, we lost 5% of our weather stations per year for thirty years. Let us suppose that 10% of these disappearing stations were subject to +0.1°C/yr warming for twenty years prior to their disappearance, as a result of urban heating. At any time during these thirty years, a total of 10% of our stations are experiencing 0.1°C/yr warming. Our combined trend will be affected by 0.01°C/yr. Over thirty years, this false trend would give us an apparent warming of 0.3°C, caused soley by urban heating.
We noted earlier the striking correlation between the number of weather stations used to obtain the global surface temperature and the apparent 0.6°C rise in global temperature between 1960 and 1990. Now we see a perfectly straight-forward manner in which the drop in the number of weather stations could be the cause of this 0.6°C rise.
Let us test our hypothesis by removing the final twenty years of measurements from all weather stations that existed prior to 1950 but disappeared some time between 1950 and 2008. We re-calculate the global trend using our method of Integrated Derivatives, which we described above. You will find our analysis code here. We plot the resulting trend below, and compare it to our original trend.
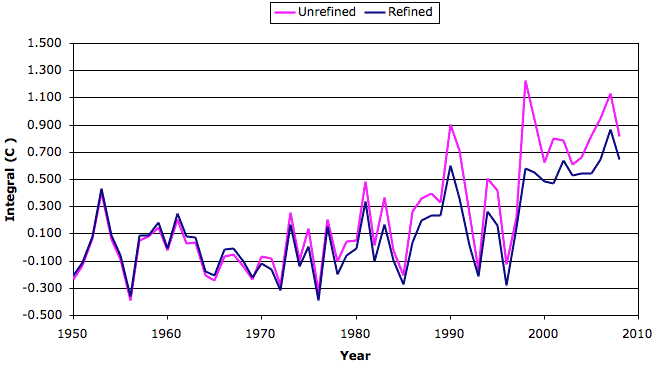
As you can see, the refined trend is consistently lower than the original trend starting from about 1970, but most of the temperature rise from 1970 to 2000 remains intact. During the 36-year period from period 1970 to 2006, the slope of the original trend is 0.027°C/yr and that of the refined trend is 0.021°C/yr. For a graph of the number of stations available with and without the disappearing stations, see here, where the original number is in pink and the refined number is in blue.
Our Analysis_6.pas program selects only those weather stations that provide a continuous record of measurements during a specified period. If the record is continuous before and after this period, we select the entire continuous history of the station. We selected period 1960 to 2000 and obtained the following graph, which shows the trend we obtain from the stations that were in continuous operation during this period, and compares it to the trend we obtain from all available stations.

Only 73 stations meet our requirements out of the thousands in the global records. Of these, two operate continuously from 1825 to the present day. Despite being based upon so few stations, our new trend is similar to the one based upon all available stations. There are, however, subtle but significant differences. In the continuous-station trend, the 1940s appear as hot as the 1990s.
Extra: Trend from stations that report for at least 80% of years 1960 to 2000, graph. Trend from stations that report for at least 80% of years 1840 to 1880, graph.
Now we select only the final twenty years of measurements from disappearing stations. Each year, we use only the measurements from stations that will disappear from our records less than twenty years later.

There are thousands of disappearing stations. They outweight the continuously-operating stations by a hundred to one. The disappearing stations suppress the warming in the 1940s and promote the warming in the 1990s. We conclude that station disappearance has a profound effect upon the significance of warming in the 1990s. With continuously-operating stations, the warming in the 1990s is no greater than that in the 1940s, but with the disappearing stations, the 1990s warming looks remarkable. All other things being equal, we trust the observations made by continuously-operating stations far more than the measurements we obtain from a diverse array of short-lived stations, so we are now inclinded to doubt the significance of the 1990s warming.
Below is a graph of the average temperature on the continental United States, plotted from data we obtained directly from NASA here.
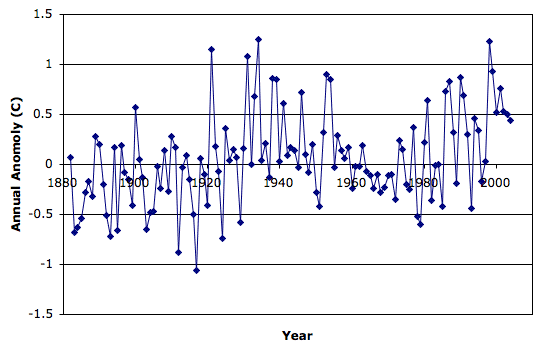
The standard deviation of the annual anomaly is 0.5°C. There is variation from year to year. This variation could be random. If it is random, we don't know what type of random distribution it follows. Is it the guassian distribution we encounter in thermal noise, or the 1/f distribution we encounter in thermal drifts of semiconductor components, or the Kolmogorov distribution we encounter in atmospheric turbulence?
It's not clear to us what we can learn from looking at the hottest year or the coldest year. The hottest year is 1934. The coldest year was 1917. If we were living through 1934, would we fear that 1935 was going to be even hotter? Perhaps, but it's not clear that the summer of 1934 was particularly hot. It could be that the winter was particularly mild. It could be that the summer of 1933 was very hot, followed by a very cold winter, making the annual anomaly come out close to zero.
Because 1934 is the hottest year, does that mean the world is cooling down? We don't think so. The year 1998 was almost as hot. The graph is so variable that the hottest and coldest years are of little help in figuring out a long-term trend. If the hottest and coldest years are not much help, how about a running average? If we take the ten-year average, maybe that will help us. But we will then be faced with the hottest ten-year average and the coldest ten-year average. How will we know if these are significant? We don't have enough data to judge the significance of the ten-year average.
In November 2009, a file called FOIA2009.zip containing thousands of e-mails and documents was downloaded from a CRU server and spread around the Internet, initiating the Climategate scandal. We downloaded the zip archive, opened it up and used "grep -Ri artificial *" to obtain a list of all files containing the word "artificial". Our interest was code that added artificial corrections to raw data, in order to give the data a positive trend in temperature with time. We found briffa_sep98_e.pro, a piece of IDL code that loads data from a series of files, each of which contains an array of temperature anomalies obtained from studies of tree-rings, like this one (also called maximal density tree-ring data, or MXD). The program adds an artificial correction to the data with the following lines and plots the data.
;****** APPLIES A VERY ARTIFICIAL CORRECTION FOR DECLINE********* ; yrloc=[1400,findgen(19)*5.+1904] valadj=[0.,0.,0.,0.,0.,-0.1,-0.25,-0.3,0.,-0.1,0.3,0.8,1.2,1.7,2.5,2.6,2.6,$ 2.6,2.6,2.6]*0.75 ; fudge factor
Only two files appear to contain the correction shown above (briffa_sep98_e.pro and briffa_sep98_d.pro). We discovered no further matches for "ARTIFICIAL CORRECTION" in the code, nor "fudge factor".
We did not find the tree-ring data files alongside the code file, but we obtained some northern-hemisphere data from NCDC, which we duplicate here. No units are given for the corrections in the program. We recall that we had to "divide three-digit temperatures by ten to obtain Centigrade" when we re-formatted the global temperature station data. So let's assume that the above corrections should be divided by ten to give Centigrade also. We obtain the following plot.

We obtained the following graph here, at the University of East Anglia, home of the Climatic Research Unit (CRU). The graph is ten years old. So is this e-mail, in which Phil Jones of CRU talks about "hiding the decline" in the Briffa tree-ring data. He writes to Michael Mann (who composed the Hockey Stick graph), and copies Briffa. As we have seen already, the uncorrected Northern-Hemisphere tree-ring data shows a decline after 1960.

We asked Gavin Schmidt of NASA whether the artificial corrections shown above were used in any of NASA's graphs. He said no, they were not. You will find our exchange buried in the comments here (or in our local copy here). He states that the graphs he has worked on continue the Briffa curve by "smoothing" the Briffa measurements using "instrumental data". We're not sure which instruments were used to obtain the additional data, nor are we sure what he means by "smooth". Gavin did point us to more recent graphs, in which the Briffa curve ends in 1960, before its decline becomes visible.
Gavin Schmidt refers to the global surface temperature measurements as the "actual temperatures". Phil Jones calls them the "real temperatures". From this we conclude that some climate scientists have a great deal of faith in the global surface measurements. In this case, the Briffa data was ignored or corrupted when it deviated from the surface temperatures (the "instrumental data"). In a similar manner, the satellite measurements were corrected until they showed an upward trend.
In 1998, Nature magazine published a paper called Global-scale temperature patterns and climate forcing over the past six centuries by Mann et al. This paper was the original source of the Hockey-Stick graph, which shows a stable climate for the past thousand years, followed by a sharp increase in the past forty years. The graph shows no sign of the medieval warming period of the elventh century, nor the little ice age of the seventeenth century. The Mann et al. paper was critisized by McIntyre et al. in Hockey Sticks, Principal Components, and Spurious Significance, which was published in Geophysical Letters in 2005. The central claim of McIntyre et al. was that the method used by Mann et al, the MBH method, produces the hockey-stick shape even if supplied with random data. So intense was the ensuing controversy that the US Congress comissioned the Wegman Report from a panel of statisticians. The Wegman Report agreed with McIntyre's central claim.
We were surprized to see that the Wikipedia entry on the Hockey-Stick Controversy does not mention the suggestion that random data generates a hocky-stick shape. We logged in and edited the entry at 11:17 on 06-DEC-09. By 4:51 pm that day, our addition had been deleted by another editor. So we posted it again, someone removed it two hours later. We'll keep re-posting it until we get bored of doing so. Here's what we wrote.
The report found that the MBH method creates a hockey-stick shape even when supplied with random input data (Figure 4.4). The MBH method uses weather station data from 1902 to 1995 as a basis for calibrating other input data. "It is not clear that Dr. Mann and his associates even realized that their methodology was faulty at the time of writing the MBH paper. The net effect of the decentering is to preferentially choose the so-called hockey stick shapes." (Section 4)
We read through the Wegman report and several of McIntyre's explanations over at Climate Audit. We believe we understand how the MBH method produces the hockey-stick graph from random (red noise) inputs, and we shall endeavor to explain. The trick is to start with absolute faith in the global surface trend generated by CRU, and use this trend to offset, scale, and even invert the trends found in other temperature histories so that they conform as closely as possible to the CRU trend. By this means, there is no possibility that any other temperature history can contradict our original assumption of warming in the twentieth century.
The MBH method calibrates all other temperature histories with respect to the CRU trend during a calibration period of 1902-1995. The calibration involves subtracting a constant and multiplying by a scaling factor. Suppose we have a temperature history A, which might be tree rings, ice cores, or any other form of measurement. The MBH method subtacts a constant from A and multiplies the result by a scaling factor so as to minimized the mean square difference between A and the CRU trend during the calibration period. We now have Ac, a calibrated version of A. We calibrate all other available temperature histories, A through Z, using the same steps, to produce Ac through Zc.
The MBH method picks the calibrated history with the largest standard deviation and combines it with the CRU trend to produce the an infant Hockey-Stick graph. The method picks the calibrated history with the next-largest standard deviation and adds it to the infant Hockey-Stick as well, but this time with less weight than the first history. The method continues adding calibrated histories to the maturing Hockey-Stick graph, each with less weight than the last, until all histories have been added.
Let us suppose A has an uniform upward trend during 1902-1995, but no variation elsewhere. During calibration, A will be shifted down when we center it upon the 1902-1995 calibration period, because the CRU trend is upward during this period. The shifted version of A will pass through zero a around 1950. As a result, the shifted A will be negative from year 1000 to 1900. We now scale A so that its variations during the 1902-1995 period match those of the CRU trend as closely as possible. (We choose the offset and scaling factor so as to minimise the mean square difference between Ac.) The Ac graph have a large standard deviation because it is poorly centered with respect to its thousand-year history, even though it is well-centered in the calibration period.
Suppose B has a downward trend during 1902-1995, but no variation elsewhere. Calibration will shif B upwards at first, when we center the history in the calibration period, but when we scale it to match the variation between 1902-1995, we use a negative scaling factor, so that its downward trend becomes an upward trend, and we minimize the mean square difference between Bc and the CRU trend. Thus, even data that shows a downward trend in temperature from 1902-1995 gets flipped around, and now acts as further evidence that temperatures were rising in 1902-1995.
Example: One temperature history that Mann et al. handles in exactly this way is the Tiljander sediment series. The Tiljander series suggests cooling during the twentieth century, but the MBH method inverts the history so that it suggests warming.
Note: In the latest versions of the Mann code, it appears that the flipping is done by taking the absolute value of the trend, so the answer is always positive, but we're not absolutely sure, see here.
If C has no trend up or down in 1902-1995, Cc remains well-centered. Its fluctuations may be amplified by scaling, but the calibrated history's standard deviation remains small compared to that of Ac and Bc. The Cc history crosses zero frequently, while the other two are offset permanently before 1902. The MBH method adds histories like Cc to the maturing Hockey-Stick after A and B, and with less weight. Histories like C produce the gray measurement error bands around the Hockey-Stick, but they do not affect the hockey-stick shape.
And so it is that the MBH method's implicit trust in the CRU trend results in all other temperature histories being manipulated into supporting evidence for the CRU trend, or simply ignored. Even a graph that shows cooling gets flipped over so that it matches the CRU trend, and acts as evidence of warming.
For a recent academic paper on the statistical invalidity of the hockey stick graph, see A Statistical Analysis of Multiple Temperature Proxies: Are Reconstructions of Surface Temperature Over the Last 1000 Years Reliable? by McShane et al.
Hence the expression "Mann-Made Global Warming". The MBH method uses the CRU trend to massage other histories into the hockey-stick shape. But note that the MBH method did not itself create the CRU trend. That was the job of CRU. We discuss the reliability of that trend elsewhere.
In a section above, we introduced our own way of analyzing global station data to generate a global temperature trend. Here we attempt to provide a more detailed argument supporting our claim that our Integrated Derivatives (ID) calculation is closely related to the CRU and NCDC calculations. Because each reader has a slightly different picture of the CRU method, we will attempt to provide an answer that applies to all such pictures.
Let's start with the following simplifying assumptions. We will discard each assumption later, as our argument progresses.
Now imagine applying the CRU method to such data. In particular, consider the years 1902 and 1903. What data does the CRU method need to calculate how much warmer was 1903 than 1902? Does it need the measurements made in 1904? Surely not, because the temperature in 1904 has not yet occurred at the end of 1903, and so cannot affect the temperature in 1903 or 1902. The same argument applies to any other year after 1903. Does the CRU method need the temperature in 1901? Surely not, because if our data-taking began in 1902, we would still be able to determine the warming from 1902 to 1903, and the past history of warming or cooling would not change our determination.
The only way for the CRU method to require data outside 1902 and 1903 is if the method has built into it some kind of long-term smoothing, so that it cannot calculate trends up to the present day, nor from the start of reliable data. If you think the CRU data has such smoothing, then consider a CRU method without smoothing, follow our argument, and then apply your smoothing at the end. All operations we describe are linear, so smoothing has the same affect whether applied before or after the operations.
The CRU method needs only the data from years 1902 and 1903 to determine the warming from 1902 to 1903. So what does the CRU method do with the temperatures from 1902 and 1903? Suppose we had the following data, consisting of four stations.
| Year | No1 | No2 | No3 | No4 |
|---|---|---|---|---|
| 1902 | 10 | 6 | −45 | 30 |
| 1903 | 11 | 7 | −44 | 31 |
One thing the CRU method could do is take the average of 1903 stations and subtract the average of 1902 stations. That would give a warming of 1°C in this case. Or the CRU method might calculate the average change in station temperature. That would give a warming of 1°C. The ID method calculates the average derivative, which is the same as the average change, and so is equal to 1°C.
Another thing the CRU method could do is assign the various stations different weights in its calculation. But our stations are, for the moment, uniformly distributed and none of them disappear, so there is no physical basis for weighting them differently. Thus, under our assumptions, the CRU and ID methods are identical.
Now let us suppose that we have some disappearing stations, which are replaced immediately by another station very close to the original location, so that our stations remain distributed uniformlly.
| Year | No1 | No2 | No3 | No4 | No5 | No6 |
|---|---|---|---|---|---|---|
| 1902 | 10 | 6 | −45 | 30 | 12 | NA |
| 1903 | 11 | 7 | −44 | 31 | NA | 16 |
In this case, let us assume that the new No6 station is in a warmer location, even though it is very close to the former station. How does the CRU method make use of stations No5 and no6? Because they are in the same location, does the CRU method assume a 4°C jump in temperature from one year to the next? If so, then the change in station location introduces an error into the trend. If such station-change errors are to be avoided, we must compare each station only with its own measurements, so that we are sensitive to the trend at a station, but not to the offsets between stations.
Thus the CRU method cannot use No5 or No6 unless it smooths earlier or later data into the missing period. Perhaps the CRU method does that (so far as we are concerned it doesn't, but we don't want to argue about the exact nature of the CRU method with our readers). The CRU method produces the answer 1°C, just like the ID method.
How much warmer is 1904 than 1902?
| Year | No1 | No2 | No3 | No4 | No5 | No6 |
|---|---|---|---|---|---|---|
| 1902 | 10 | 6 | −45 | 30 | 12 | NA |
| 1903 | 11 | 7 | −44 | 31 | NA | 16 |
| 1904 | 12 | 8 | −43 | 32 | NA | 17 |
Let's start with the change form 1903 to 1904. We subtract the average temperature in 1903 from the average in 1904 and get 1°C warming. This is also the average derivative. The CRU and ID methods agree about 1903 to 1904. We already showed that they agree about 1902 to 1903. So they must agree about 1902 to 1904 as well. The CRU and ID methods give +2°C for 1902 to 1904.
Let us generalize our argument. For years N and M, such that M>N, the warming from year N to M is the sum of the warming from year p to p+1, for years p=N to M−1. But we have shown that the warming from year p to p+1 is the same for the ID and CRU methods, subject to our existing assumption of uniform distribution. Thus the ID and CRU methods produce the same results for uniformly-distributed weather stations.
| Year | No1 | No2 | No3 | No4 | No5 | No6 |
|---|---|---|---|---|---|---|
| 1902 | 10 | 6 | −45 | 30 | 12 | NA |
| 1903 | 11 | 7 | −44 | 31 | NA | 16 |
| 1904 | 12 | 8 | −43 | 32 | NA | 17 |
| 1905 | 12 | 7 | −44 | 33 | NA | 17 |
| 1906 | 13 | 9 | −41 | 34 | NA | 18 |
| 1907 | 13 | 10 | −44 | 35 | NA | 21 |
| 1908 | 16 | 12 | −42 | 36 | NA | 19 |
The CRU and ID methods produce the same answer for the above data. We invite you to prove this to yourself if you are in doubt. Keep in mind that the stations are in this example uniformly distributed.
When the weather stations are not uniformly distributed, the CRU and ID methods begin to differ. The CRU method gives less weight to stations that are close together, and more weight to stations that are isolated. In each year, the ID method gives us the unweighted average derivative, while the CRU trend gives us a weighted average derivative. Both methods add their derivatives up in the same way. No one year is given more weight in the intergral than another.
The CRU reference grid is part of the weighting-selecting procedure, and also gives the CRU trend an absolute value in the 1960-1990 reference period. The ID method provides no absolute value, but we could obtain one easily enough. Look at the graph of the average anomaly here. In the year 1960, this graph has value 12.5°C. We could use that as our constant of integration. But our global average won't be accurate. The CRU graphs are usually expressed in terms of anmalies, because they don't want to stress their global average temperature either.
We assumed we were working with annual average temperatures, but the same arguments would apply equally to monthly anomalies, with the year number replaced by a month number, and the absolute temperature replaced by the deviation from the station's average temperature.
The ID method gives equal weight to all stations. The CRU method applies a weighting factor to the measurements from each station before they calculate the annual derivative. The CRU weighting appeasr to have little effect upon the resulting trend (blue is CRU, pink is ID). And so we conclude that the ID and CRU methods are closely related, and we are justified in using the ID method as a proxy for the CRU method, when trying to determine how the CRU method would respond to new data sets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
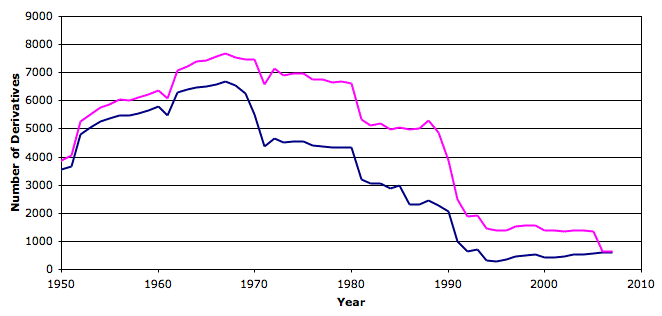{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}